
The cornerstones of LiveRamp’s products are accuracy, efficiency, and speed, which requires our solutions to be capable of scaling massive quantities of data. Our customers rely on real-time data analysis to measure the reach of advertising campaigns, and this often involves calculating the cardinality of datasets with tens of millions of users or stacking intersections and joins to create the ideal audience.
This is where LiveRamp’s Data Marketplace comes into play. It provides access to global data from the world’s top providers which can be easily activated across technology and media platforms, agencies, analytics environments, and TV partners. In order to get the most use out of this data, customers need to be able to dynamically union and intersect large segments of data to build effective campaigns and estimate their reach.
For example, a client might want to build an audience for an ad that will be shown to consumers who have expressed interest in travelling, spas, and hiking destinations. The client wants to intersect all three segments of consumers, each of which has millions of members, and immediately know the size of the resulting intersection so they can add or remove segments to tune and build their campaign in one sitting.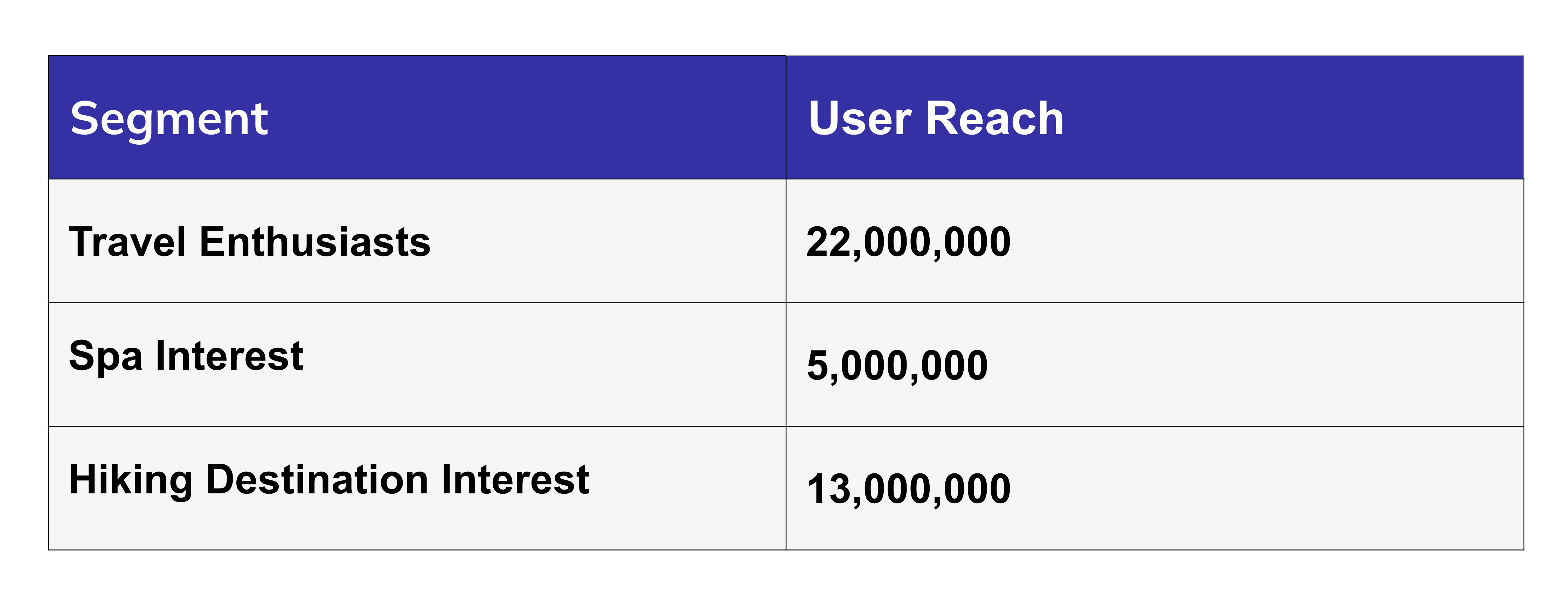

Many approaches to cardinality estimation involve storing all the unique elements of a dataset in memory, which is both computationally expensive and memory-inefficient. Instead, we use HyperMinHash (HMH) sketches to power instantaneous queries on massive datasets, carefully balancing the tradeoff between query speed and sketch precomputation.
The HMH algorithm belongs to a family of algorithms that represent big data as small probabilistic data structures known as sketches. This family includes the HyperLogLog (HLL) and MinHash algorithms, which also use random hash functions to generate sketches for estimating cardinality. HMH sketches have many advantages that make them well-suited to powering the architecture behind cardinality estimation at scale:
- Terabytes of data can be represented in megabytes as hashed sketches.
- Using sketch representations of segments decouples the process of cardinality estimation from the data itself, so copies of the data do not need to be passed around different environments. This aligns with LiveRamp’s core values of security and privacy.
- HMH sketches can be unioned and intersected (when combined with Jaccard similarity), meaning they can power a fast and memory-efficient boolean query language.
- HMH sketch union and intersection operations are processed on the order of milliseconds, so they can provide real-time results for complex joins.
- A HMH sketch does not grow in size as it counts elements, so the storage cost associated with HMH sketches is both low and consistent despite increasing data size.
- Sketches can be computed and combined in a distributed system, and their computation can be highly optimised across a cluster.
The Math Behind HyperMinHash (HMH) Sketches
HyperMinHash is a lossy compression of MinHash and was published in 2017 by Yu and Weber. LiveRamp was the first to release an open source Java implementation of the algorithm.
To understand the math behind HyperMinHash sketches, it is easier to start with their predecessor, MinHash sketches. The MinHash algorithm estimates the Jaccard index (also known as Intersection-over-Union), which is the ratio of the intersection to the union between two sets. MinHash uses the mathematical fact that if you apply a random hash function over all the elements in two sets A and B, the probability that the smallest element for set A is the same as the smallest element for set B is equivalent to the Jaccard index. Intuitively, this comes from the idea that every element in the hashed set has equal probability of being the minimum element. This intuition is formalised in notation from Yu and Weber’s paper.
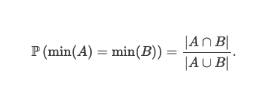
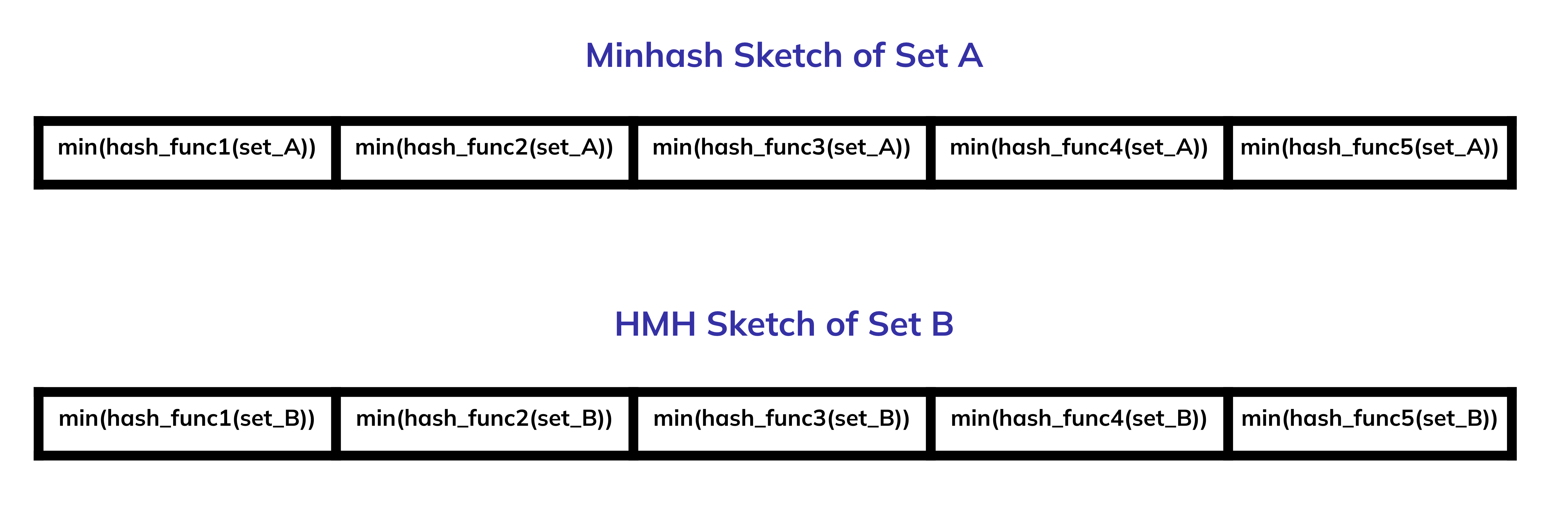
The MinHash algorithm utilises a set of K hash functions to create a vector of minimum values from the output of each hash function. The MinHash sketch itself is this vector: an array of minimum values from hash functions whose size is determined by the number of hash functions used (or the desired precision).
Here is a visualisation of two hypothetical HMH sketches where five hash functions are used. The actual values saved inside an HMH sketch are optimised further to save as little data of the minimum value as possible (HyperMinHash in particular optimises the memory by only saving the order of magnitude and mantissa of the binary expansion of the minimum) but intuitively speaking, sketches are arrays of minima.
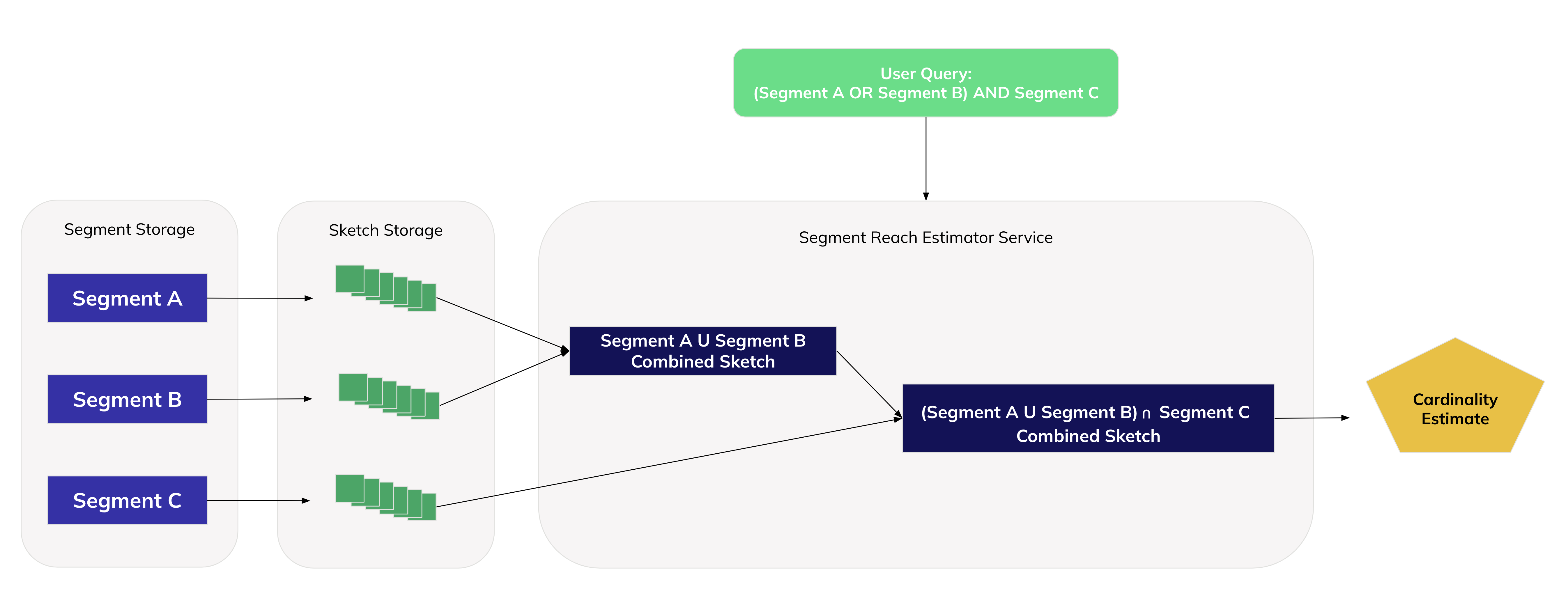
HMH Architecture for Segment Building and Trade-Offs
Sketches are memory efficient and take up very little space when stored and combined, but they must be already available when clients submit their queries. Otherwise clients must wait for the sketch to be generated, which would delay their session and make their queries process at a slower rate. The key stake in a sketch-based architecture is to balance the speed and memory efficiency of the HMH sketches with the cost and time involved with precomputing them.
Sketch Generation
Our clients send us millions of segments, so it would be cost-prohibitive to precompute sketches on all of them. Currently we enable sketches for tens of thousands of segments for our Data Marketplace and activation customers.
When a customer enables one of their segments for reach statistics, a Spark job is triggered to generate a sketch for that segment. Once the sketch is generated, its storage path is added to a database that maps segments to their corresponding sketch paths and maintains a cache.
When a user submits a query for segment combination, the sketches for the segments involved in that query are retrieved from storage and combined within milliseconds. The final sketch’s cardinality estimate is returned to the user in the UI where they can use its information to adjust the size and contents of their final audience.
Sketches by Activation Destination
Segments also have reach statistics that are dependent on their downstream activation destinations. Our products offer activation on many services such as The Trade Desk, Yahoo, Adobe Cloud, and more. A segment’s reach depends on where it is activated. So if there are, for example, 10 destinations, a given segment has 10 possible reach estimates. In our current architecture, we generate separate sketches for each destination, meaning a single segment is associated with 10 different sketches. We are planning to reduce this to just one sketch for all destinations by using heuristics and machine learning.
Caching
We performed product research proving that data refreshes rarely change the contents of a segment significantly. It would be expensive to refresh the database of sketches more frequently than they need to be updated. To limit unnecessary computation, segment sketches are only refreshed once every thirty days and only if the underlying segment data has been updated within that time window. If the segment has not been updated, there is no need to update its sketch. Limiting sketch updates to every thirty days was an acceptable cadence for our users.
Future Work
Reducing Sketch Overhead
As discussed above, generating multiple sketches for the same segment is not ideal. It adds compute overhead to enabling a new segment for reach statistics, and it makes adding a new destination for activation expensive as we must generate sketches for all segments using that destination. Our long-term goal is to scale the number of segments we have enabled for this service and to activate against more destinations, so the obvious problem becomes reducing our sketch count to enable this expansion.
In the next year we plan to explore alternative architectures that use only one sketch for a segment and use machine learning functionality to make inferences for destination reach. A given client has a host of metadata associated with their usage, such as their historical match rates against a given destination, the average size of their segments, the variability of their reach against a destination, etc. We plan to benchmark models that are trained on this information to predict the reach adjustment for an activation destination. In this workflow all segments are represented as a single sketch, and when customers request the reach for a specific destination, a model supplies additional information on that segment’s expected reach.
Privacy-Centric Design
As the industry moves towards cloud interoperability, it will become increasingly important to develop tools that limit the transfer of data outside of customer environments while still enabling cross-cloud data collaboration. Transferring data between secure environments to perform sensitive joins is an expensive task.
One of the key benefits of sketches is their ability to represent source data accurately without fully exposing its contents. As long as sketches use the same hash functions and registers, they can be passed between cloud environments and products very cheaply and efficiently.
As LiveRamp moves toward a composable, cloud-agnostic future, we will continue to invest in solutions that prioritise security and privacy in efficient and cost-effective ways.